자연어 처리는 주로 순환 신경망 (RNN) 이용
keras의 자연어 처리 라이브러리 nltk를 사용한다.
자연어 처리 단계
자연어 처리 전 필요없는 토큰(불용어) 제거하는 과정 필요
1) 텍스트 전처리
- 토큰으로 분리(토큰화)
import nltk
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
- 각종 구두점 삭제
- 소문자 변환
신경망이 소화할 수 있는 방식으로 단어를 제공해야함!!
1) 정수 인코딩
- 일반적으로 단어를 빈도 순으로 정렬 한 뒤 번호를 차례대로 부여한다.
2) 원핫 인코딩
- 이진벡터 중 하나만 1이고 나머지 0으로 변환

keras의 to_categorical() 함수 사용
import numpy as np
from keras.utils import to_categorical
text= ["cat","dog","cat","bird"] #변환하고 싶은 텍스트
total_pets= ["cat","dog","turtle","fish","bird"] #단어 집합
print("text=", text)
mapping={} # 변환에 사용되는 딕셔너리 만들기
for x in range(len(total_pets)):
mapping[total_pets[x]]=x
print(mapping)
for x in range(len(text)): # 순차적인 정수 인덱스로 만들기
text[x]= mapping[text[x]]
print("text=",text)
one_hot_encode= to_categorical(text) #순차적인 정수 인덱스를 원-핫 인코딩으로 만듬
print("text=", one_hot_encode)
그러나 비효율적!
0인 벡터가 너무 많이 만들어짐, 유사도 표현 불가능
3) 워드 임베딩
- 하나의 단어를 밀집 벡터로 표현하는 방법
- 훈련 데이터에서 자동으로 생성하는 것이 일반적 (신경망 사용)
Word2vec
CBOW
- 주변에 있는 단어들로 중간에 있는 단어 예측

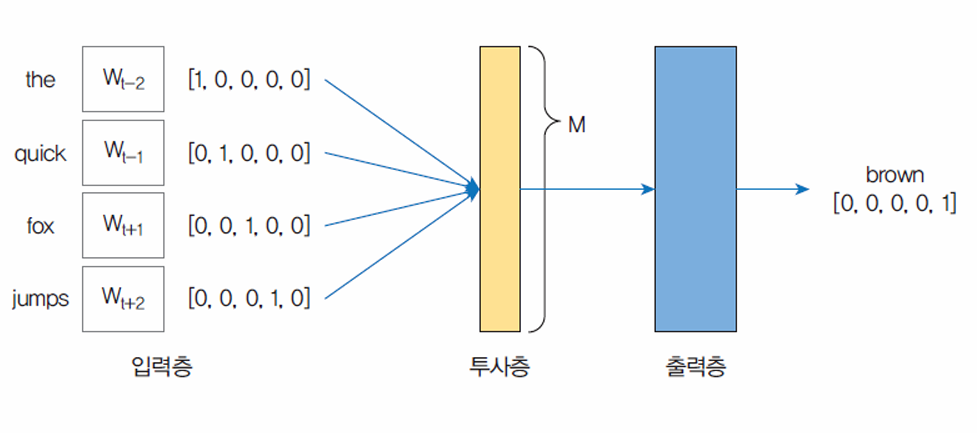
맥락 -> 주변 단어
타겟 -> 중앙 단어
skipgram
- 중간에 있는 단어로 주변 단어들 예측

texts_to_sequences() : text 데이터를 숫자 시퀀스로 변환
pad_sequences(sequences(시퀀스 데이터), maxlen(샘플 최대길이)=None, padding='pre', truncating='pre', value=0.0) : 패딩을 수행하는 함수
padding= 'pre' 이면 앞에 0, 'post'면 뒤에 0 을 채움
from tensorflow.keras.preprocessing.sequence import pad_sequences
X= pad_sequences([[7,8,9],[1,2,3,4,5],[7]], maxlen=3, padding='pre')
print(X)
e = Embedding(input_dim, output_dim, input_length=100)
input_dim: 어휘 크기. 데이터 0~9 사이의 값 정수 인코딩 된 경우 어휘 크기 10
output_dim: 각 단어에 대해 레이어의 출력 벡터 크기 정의
입력 형태 : 2D 텐서 (batch_size, sequence_length)
출력 형태: 3D 텐서 (batch_size, sequence_length, output_dim)
import numpy as np
from tensorflow.keras.layers import Embedding
from tensorflow.keras.models import Sequential
(batch_size, input_length)=(32,3) #입력 형태
(None, 3,4) # 출력 형태
model= Sequential()
model.add(Embedding(100,4, input_length=3))
input_array= np.random.randint(100, size=(32,3))
model.compile('rmsprop','mse')
output_array = model.predict(input_array)
print(output_array.shape)
Embedding layer를 통해 정수를 고차원 벡터로 변형시킨다.

과정
1) 텍스트 데이터 정수화하고 패딩
2) 단어를 임베딩 벡터로 변환
3) 신경망 학습 후 분류모델 구축
4) 새 텍스트 데이터에 대해 긍정/부정 클래스 예측
스팸메일 분류하기 예제 코드
import numpy as np
from tensorflow.keras.layers import Embedding, Flatten, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import one_hot
from tensorflow.keras.preprocessing.sequence import pad_sequences
docs = [ 'additional income',
'best price',
'big bucks',
'cash bonus',
'earn extra cash',
'spring savings certificate',
'valero gas marketing',
'all domestic employees',
'nominations for oct',
'confirmation from spinner']
labels = np.array([1,1,1,1,1,0,0,0,0,0])
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs] #정수로 바꿈!
print(encoded_docs)
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post') # 패딩 처리
print(padded_docs)
model = Sequential()
model.add(Embedding(vocab_size, 8, input_length=max_length)) # 8차원 임베딩 벡터로
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(padded_docs, labels, epochs=50, verbose=0)
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('정확도=', accuracy)
test_doc = ['big income']
encoded_docs = [one_hot(d, vocab_size) for d in test_doc]
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(model.predict(padded_docs))
단어 예측하기 전체 코드
import numpy as np
from tensorflow.keras.layersimport Embedding, Flatten, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import one_hot
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
text_data="""Soft as the voice of an angel\n
Breathing a lesson unhead\n
Hope with a gentle persuasion\n
Whispers her comforting word\n
Wait till the darkness is over\n
Wait till the tempest is done\n
Hope for sunshine tomorrow\n
After the shower
"""
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text_data])
encoded = tokenizer.texts_to_sequences([text_data])[0]
print(encoded)
print(tokenizer.word_index)
vocab_size = len(tokenizer.word_index) + 1
print('어휘 크기: %d' % vocab_size)
sequences = list() #입출력 시퀀스 생성
for i in range(1, len(encoded)):
sequence = encoded[i-1:i+1]
sequences.append(sequence)
print(sequences)
print('총 시퀀스 개수: %d' % len(sequences))
sequences = np.array(sequences)
X, y = sequences[:,0],sequences[:,1]
print("X=", X) #입력 값
print("y=", y) #출력 값
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam’,metrics=['accuracy’])
model.fit(X, y, epochs=500, verbose=2)
# 테스트 단어를 정수 인코딩한다.
test_text= 'Wait'
encoded = tokenizer.texts_to_sequences([test_text])[0]
encoded = np.array(encoded)
# 신경망의 예측값을 출력해본다.
onehot_output= model.predict(encoded)
print('onehot_output=', onehot_output)
# 가장 높은 출력을 내는 유닛을 찾는다.
output = np.argmax(onehot_output)
print('output=', output)
# 출력층의 유닛번호를 단어로 바꾼다.
print(test_text, "=>", end=" ")
for word, index in tokenizer.word_index.items():
if index == output:
print(word)'etc' 카테고리의 다른 글
| [딥러닝] 11장 순환신경망 (2) | 2024.12.08 |
|---|---|
| [딥러닝] 10장 영상인식 (1) | 2024.12.07 |
| [딥러닝] 9장 CNN (2) | 2024.12.07 |
| [딥러닝] 8장 심층신경망 (0) | 2024.12.06 |
| [딥러닝] 7장 MLP-2 (2) | 2024.12.06 |